跳表解析-ConcurrentSkipListMap源码分析
ConcurrentSkipListMap提供了一种线程安全的并发访问的排序映射表。内部是SkipList(跳表)结构实现,在理论上能够在O(log(n))时间内完成查找、插入、删除操作。
ConcurrentSkipListMap数据结构
上一篇跳表基础篇讲解了跳表的演变,在此在不做赘述。下边是ConcurrentSkipListMap的数据结构图:
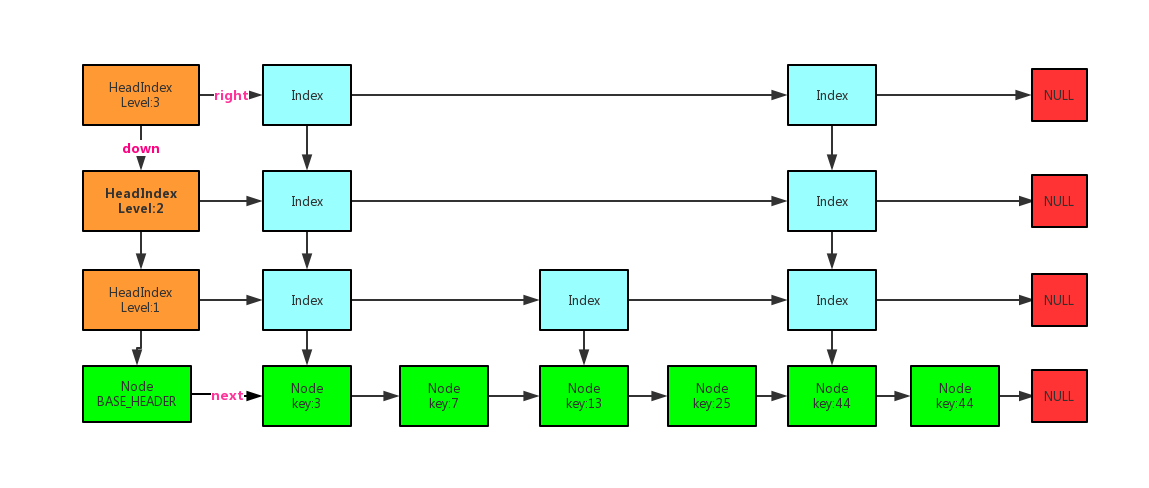
ConcurrentSkipListMap源码分析
类继承体系
public class ConcurrentSkipListMap<K,V> extends AbstractMap<K,V>
implements ConcurrentNavigableMap<K,V>, Cloneable, Serializable {}
ConcurrentSkipListMap继承了AbstractMap抽象类,实现了ConcurrentNavigableMap接口,该接口定义了获取某一部分集合的操作。实现了Cloneable接口,表示允许克隆。实现了Serializable接口,表示可被序列化。
包含的内部类:
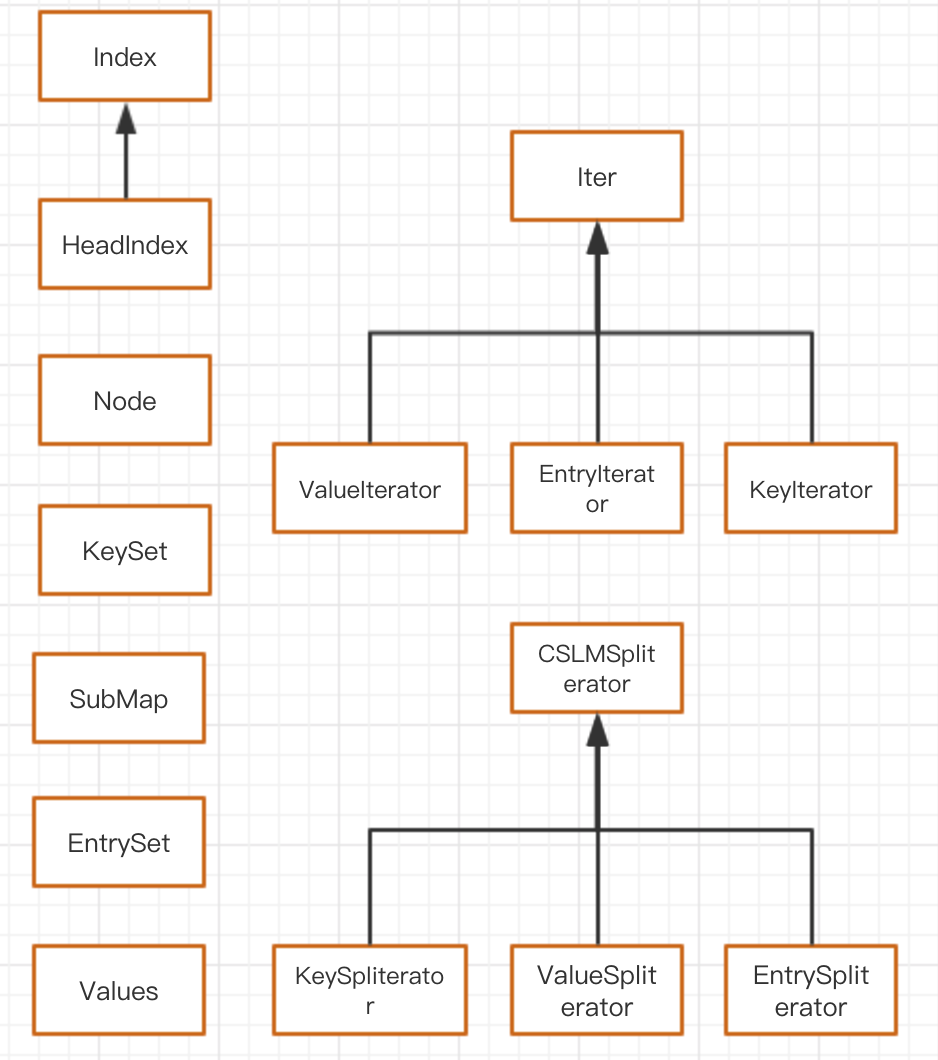
Index类源码分析
static class Index<K,V> {
final Node<K,V> node; //所包含的Node节点信息
final Index<K,V> down; //表示Index向下的down域
volatile Index<K,V> right; //表示Index向有的down域
/**
* 构造函数
*/
Index(Node<K,V> node, Index<K,V> down, Index<K,V> right) {
this.node = node;
this.down = down;
this.right = right;
}
/**
* cas操作修改right域
*/
final boolean casRight(Index<K,V> cmp, Index<K,V> val) {
return UNSAFE.compareAndSwapObject(this, rightOffset, cmp, val);
}
//用于在当前Index节点后边插入节点,并将插入节点的right域设置为当前节点的right域
final boolean link(Index<K,V> succ, Index<K,V> newSucc) {
Node<K,V> n = node;
newSucc.right = succ;
return n.value != null && casRight(succ, newSucc);
}
//删除当前Index结点的right结点
final boolean unlink(Index<K,V> succ) {
return node.value != null && casRight(succ, succ.right);
}
private static final sun.misc.Unsafe UNSAFE;
private static final long rightOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Index.class;
rightOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("right"));
} catch (Exception e) {
throw new Error(e);
}
}
}
HeadIndex类源码分析
//表示每一层的头节点
static final class HeadIndex<K,V> extends Index<K,V> {
final int level; //表示当前层级
HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) {
super(node, down, right);
this.level = level;
}
}
根据HeadIndex类可知其继承自Index类,并且在Index类的基础上添加了level域,表示当前的层级。
Node类源码分析
*/
static final class Node<K,V> {
final K key;
volatile Object value;
volatile Node<K,V> next;
Node(K key, Object value, Node<K,V> next) {
this.key = key;
this.value = value;
this.next = next;
}
//创建一个marker节点,其值指向本身,主要在删除节点时使用
Node(Node<K,V> next) {
this.key = null;
this.value = this;
this.next = next;
}
//cas操作修改value
boolean casValue(Object cmp, Object val) {
return UNSAFE.compareAndSwapObject(this, valueOffset, cmp, val);
}
//cas操作修改next域
boolean casNext(Node<K,V> cmp, Node<K,V> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
//判断是否为标记节点
boolean isMarker() {
return value == this;
}
//判断是否为头节点
boolean isBaseHeader() {
return value == BASE_HEADER;
}
//在当前节点后边添加一个标记节点
boolean appendMarker(Node<K,V> f) {
return casNext(f, new Node<K,V>(f));
}
//删除节点
void helpDelete(Node<K,V> b, Node<K,V> f) {
if (f == next && this == b.next) { //// f为当前结点的后继并且b为当前结点的前
if (f == null || f.value != f) // not already marked
// 当前结点后添加一个marker结点,并且当前结点的后继为marker,marker结点的后继为f
casNext(f, new Node<K,V>(f));
else //f不为空并且f的值为本身
b.casNext(this, f.next); //设置b的next域为f的next域
}
}
//判断当前节点是否有效(BASE_HEADER 以及标记节点无效)
V getValidValue() {
Object v = value;
if (v == this || v == BASE_HEADER)
return null;
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
//创建一个快照
AbstractMap.SimpleImmutableEntry<K,V> createSnapshot() {
Object v = value;
if (v == null || v == this || v == BASE_HEADER)
return null;
@SuppressWarnings("unchecked") V vv = (V)v;
return new AbstractMap.SimpleImmutableEntry<K,V>(key, vv);
}
// UNSAFE mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
valueOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("value"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
ConcurrentSkipListMap类属性
public class ConcurrentSkipListMap<K,V> extends AbstractMap<K,V>
implements ConcurrentNavigableMap<K,V>, Cloneable, Serializable {
// 版本序列号
private static final long serialVersionUID = -8627078645895051609L;
// 基础层的头结点
private static final Object BASE_HEADER = new Object();
// 最顶层头结点的索引
private transient volatile HeadIndex<K,V> head;
// 比较器
final Comparator<? super K> comparator;
// 键集合
private transient KeySet<K> keySet;
// entry集合
private transient EntrySet<K,V> entrySet;
// 值集合
private transient Values<V> values;
// 降序键集合
private transient ConcurrentNavigableMap<K,V> descendingMap;
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
// head域的偏移量
private static final long headOffset;
// Thread类的threadLocalRandomSecondarySeed的偏移量
private static final long SECONDARY;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = ConcurrentSkipListMap.class;
headOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("head"));
Class<?> tk = Thread.class;
SECONDARY = UNSAFE.objectFieldOffset
(tk.getDeclaredField("threadLocalRandomSecondarySeed"));
} catch (Exception e) {
throw new Error(e);
}
}
}
ConcurrentSkipListMap包含了head属性,表示跳表的头结点,并且包含了一个比较器,值得注意的是,对于ConcurrentSkipListMap的使用,键必须能够进行比较,如传递了比较器或者键本身就能够进行比较。
ConcurrentSkipListMap类构造器
1.ConcurrentSkipListMap()构造函数
// 构造一个新的空映射,该映射按照键的自然顺序进行排序
public ConcurrentSkipListMap() {
// 比较器为空,那么键必须能够比较(实现了Comparable接口)
this.comparator = null;
// 初始化相关的域
initialize();
}
构造一个新的空映射,该映射按照键的自然顺序进行排序,即键K必须实现Comparable接口,否则会报错
2.ConcurrentSkipListMap(Comparator<? super K>)构造函数
// 构造一个新的空映射,该映射按照指定的比较器进行排序
public ConcurrentSkipListMap(Comparator<? super K> comparator) {
// 初始化比较器
this.comparator = comparator;
// 初始化相关的域
initialize();
}
构造一个新的空映射,该映射按照指定的比较器进行排序
3.ConcurrentSkipListMap(Map<? extends K, ? extends V> m)构造函数
// 构造一个新映射,该映射所包含的映射关系与给定映射包含的映射关系相同,并按照键的自然顺序进行排序
public ConcurrentSkipListMap(Map<? extends K, ? extends V> m) {
// 比较器Wie空
this.comparator = null;
// 初始化相关的域
initialize();
// 将m的所有元素添加至跳表
putAll(m);
}
构造一个新映射,该映射所包含的映射关系与给定映射包含的映射关系相同,并按照键的自然顺序进行排序。
4.ConcurrentSkipListMap(SortedMap<K, ? extends V>)构造函数
// 构造一个新映射,该映射所包含的映射关系与指定的有序映射包含的映射关系相同,使用的顺序也相同
public ConcurrentSkipListMap(SortedMap<K, ? extends V> m) {
// 获取m的比较器
this.comparator = m.comparator();
// 初始化相关的域
initialize();
// 根据m的元素来构建跳表
buildFromSorted(m);
}
构造一个新映射,该映射所包含的映射关系与指定的有序映射包含的映射关系相同,使用的顺序也相同。
核心函数分析
1.doPut函数 Part I:生成新节点插入链表
//插入一个结点
private V doPut(K key, V value, boolean onlyIfAbsent) {
Node<K,V> z; // added node
if (key == null) //键为空,抛出空异常
throw new NullPointerException();
// 比较器
Comparator<? super K> cmp = comparator;
outer: for (;;) { // 无限循环
//根据 key,找到待插入的位置
//b 叫做前驱节点,将来作为新加入结点的前驱节点
//n 叫做后继结点,将来作为新加入结点的后继结点
//也就是说,新节点将插入在 b 和 n 之间
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
//如果 n 为 null,那么说明 b 是链表的最尾端的结点,这种情况比较简单,
//直接构建新节点插入即可
if (n != null) { // next域不为空
Object v; int c;
// f为当前结点的后继节点
Node<K,V> f = n.next;
//如果 n 不再是 b 的后继结点了,说明有其他线程向b后面添加了新元素
//那么我们直接退出内循环,重新计算新节点将要插入的位置
if (n != b.next)
break;
//value =null 说明n已经被标识位待删除,其他线程正在进行删除操作
//调用 helpDelete 帮助删除,并退出内层循环重新计算待插入位置
if ((v = n.value) == null) {
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n) //b结点已经被删除
break;
//如果新节点的 key 大于 n 的 key 说明找到的前驱节点有误
//按序往后挪一个位置即可
if ((c = cpr(cmp, key, n.key)) > 0) {
// b往后移动
b = n;
// n往后移动
n = f;
continue;
}
if (c == 0) { // 键相等
//比较并交换值
if (onlyIfAbsent || n.casValue(v, value)) {
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
// 重试
break; // restart if lost race to replace value
}
// else c < 0; fall through
}
//无论遇到何种问题,到这一步说明待插位置已经确定
z = new Node<K,V>(key, value, n);
if (!b.casNext(n, z)) // 比较并交换next域
break; // restart if lost race to append to b
// 成功,则跳出循环
break outer;
}
}
经过这一部分,已经将节点插入到了Node链表里边
Part II:随机决定是否需要建立索引及其层次,如果需要则建立自上而下的索引
// 随机生成种子
int rnd = ThreadLocalRandom.nextSecondarySeed();
if ((rnd & 0x80000001) == 0) { // test highest and lowest bits
int level = 1, max;
while (((rnd >>>= 1) & 1) != 0) // 判断从右到左有多少个连续的1
++level;
Index<K,V> idx = null;
// 保存头结点
HeadIndex<K,V> h = head;
if (level <= (max = h.level)) { // 小于跳表的层级
for (int i = 1; i <= level; ++i) // 为结点生成对应的Index结点
// 从下至上依次赋值,并且赋值了Index结点的down域
idx = new Index<K,V>(z, idx, null);
}
else { // try to grow by one level
level = max + 1; // hold in array and later pick the one to use
// 生成Index结点的数组,其中,idxs[0]不作使用
@SuppressWarnings("unchecked")Index<K,V>[] idxs =
(Index<K,V>[])new Index<?,?>[level+1];
for (int i = 1; i <= level; ++i) //从下到上生成Index结点并赋值down域
idxs[i] = idx = new Index<K,V>(z, idx, null);
for (;;) { // 无限循环
// 保存头结点
h = head;
// 保存跳表之前的层级
int oldLevel = h.level;
if (level <= oldLevel) // lost race to add level
break;
// 保存头结点
HeadIndex<K,V> newh = h;
// 保存头结点对应的Node结点
Node<K,V> oldbase = h.node;
for (int j = oldLevel+1; j <= level; ++j) //为每一层生成一个头结点
newh = new HeadIndex<K,V>(oldbase, newh, idxs[j], j);
if (casHead(h, newh)) { // 比较并替换头结点
// h赋值为最高层的头结点
h = newh;
// idx赋值为之前层级的头结点,并将level赋值为之前的层级
idx = idxs[level = oldLevel];
break;
}
}
}
经过上面的步骤,有两种情况:
一是没有超出高度,新建一条目标节点的索引节点链
二是超出了高度,新建一条目标节点的索引节点链,同时最高层头索引节点同样往上长
Part III:将新建的索引节点(包含头索引节点)与其它索引节点通过右指针连接在一起
// find insertion points and splice in
// 插入Index结点
splice: for (int insertionLevel = level;;) {
// 保存新跳表的层级
int j = h.level;
for (Index<K,V> q = h, r = q.right, t = idx;;) {
if (q == null || t == null) // 头结点或者idx结点为空
// 跳出外层循环
break splice;
if (r != null) { // right结点不为空
// 保存r对应的Node结点
Node<K,V> n = r.node;
// compare before deletion check avoids needing recheck
// 比较key与结点的key值
int c = cpr(cmp, key, n.key);
if (n.value == null) { // 结点的值为空,表示需要删除
if (!q.unlink(r)) // 删除q的Index结点
break;
// r为q的right结点
r = q.right;
continue;
}
if (c > 0) { // key大于结点的key
// 向右寻找
q = r;
r = r.right;
continue;
}
}
if (j == insertionLevel) {
if (!q.link(r, t)) // r结点插入q与t之间
break; // restart
if (t.node.value == null) { // t结点的值为空需要删除
// 利用findNode函数的副作用
findNode(key);
break splice;
}
if (--insertionLevel == 0) // 到达最底层,跳出循环
break splice;
}
if (--j >= insertionLevel && j < level)
t = t.down;
q = q.down;
r = q.right;
}
}
}
return null;
}
上边主要是把doPut源码分为三部分讲解,主要大体流程如下:
① 根据给定的key从跳表的左上方往右或者往下查找到Node链表的前驱Node结点,这个查找过程会删除一些已经标记为删除的结点。
② 找到前驱结点后,开始往后插入查找插入的位置(因为找到前驱结点后,可能有另外一个线程在此前驱结点后插入了一个结点,所以步骤①得到的前驱现在可能不是要插入的结点的前驱,所以需要往后查找)。
③ 随机生成一个种子,判断是否需要增加层级,并且在各层级中插入对应的Index结点。
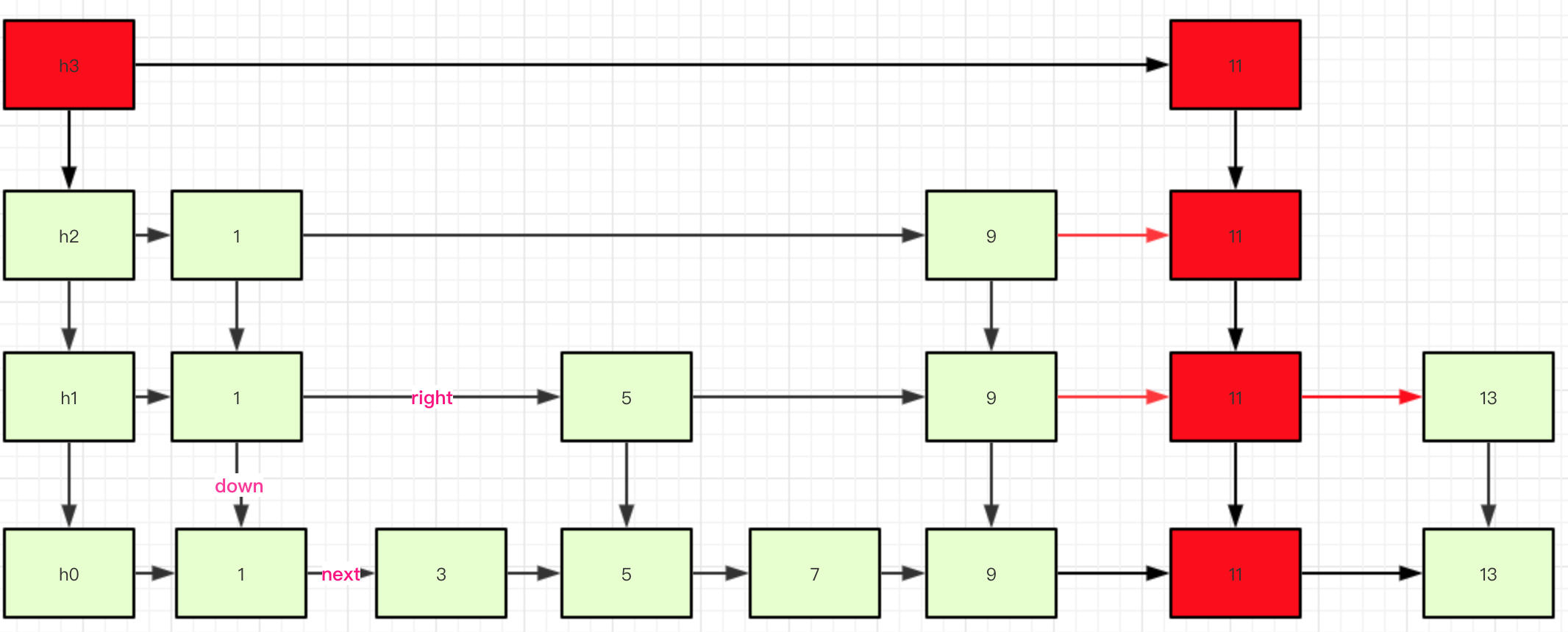
下边我们根据图形看一下doPut的流程:
假设level=4,高于当前level,则需要增加层级
第一步:新增一个结点到最底层的链表上。
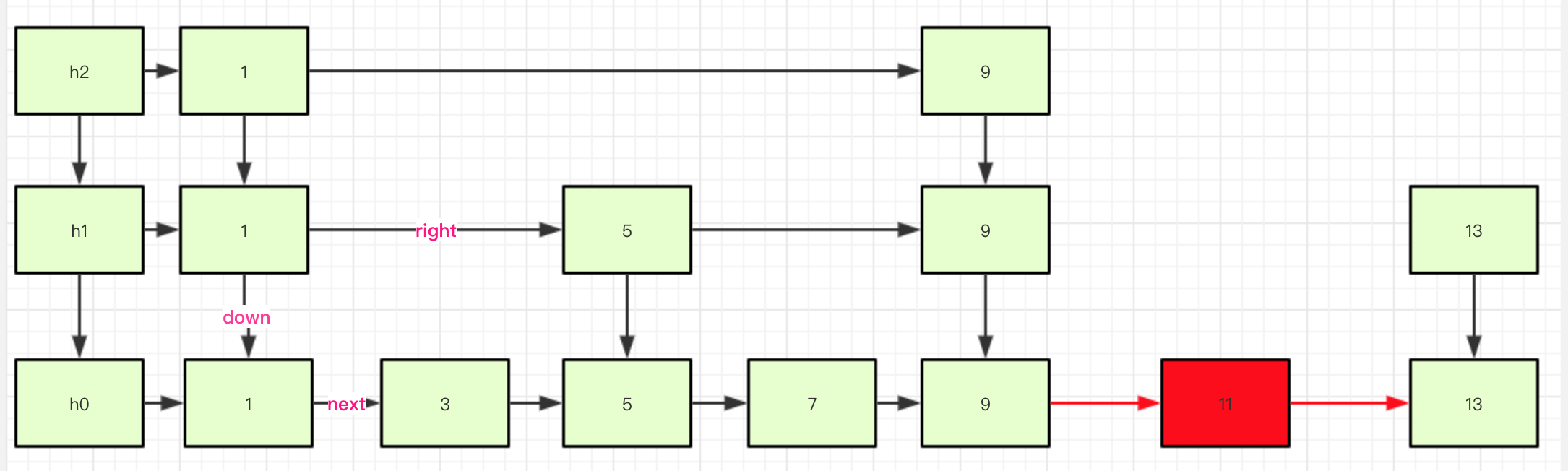
第二部:生成向下索引down(level等级高于当前,则需要在新建一个HeadIndex)
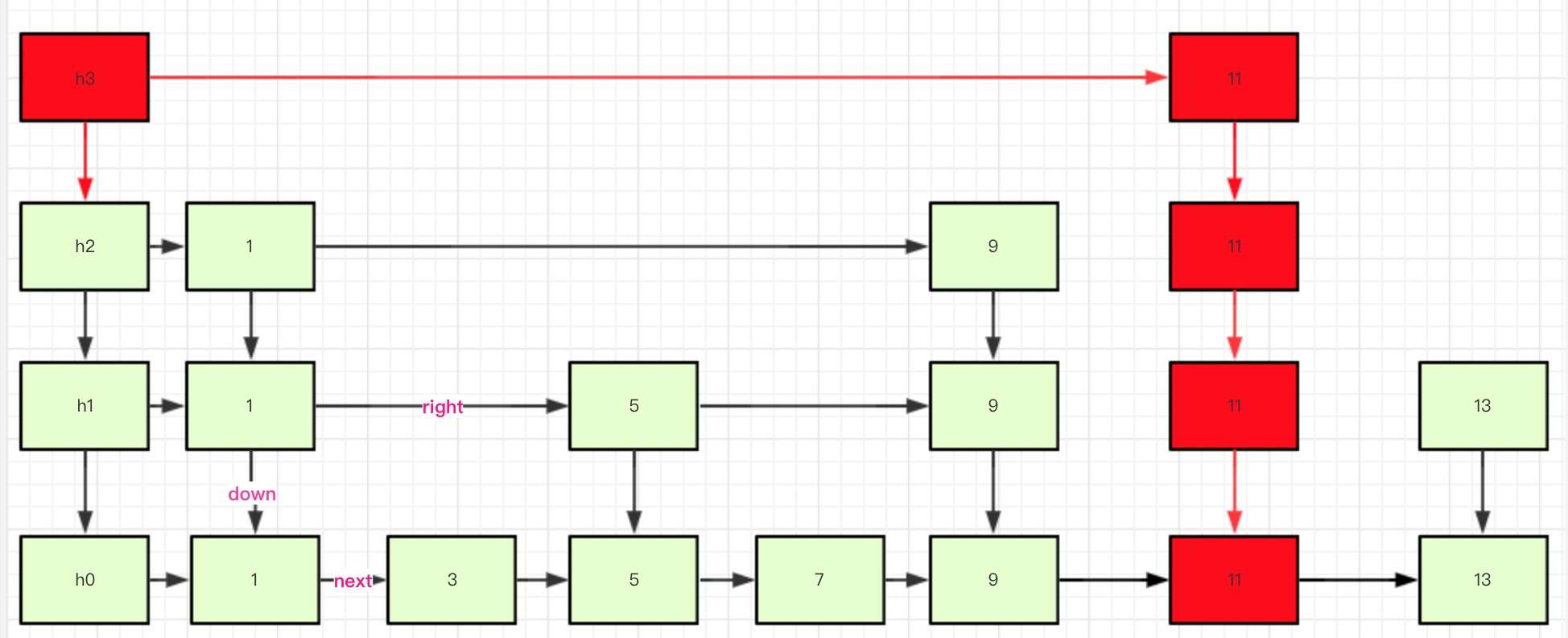
第三部分:链接各个索引层次上的新节点。
2.findPredecessor()函数
private Node<K,V> findPredecessor(Object key, Comparator<? super K> cmp) {
if (key == null) // 键为空,抛出空异常
throw new NullPointerException(); // don't postpone errors
for (;;) { // 无限循环
for (Index<K,V> q = head, r = q.right, d;;) { //
if (r != null) { // 右Index结点不为空
// n为当前Node结点
Node<K,V> n = r.node;
// 为当前key
K k = n.key;
if (n.value == null) { //当前Node结点value为空表示需要删除
if (!q.unlink(r)) // unlink r Index结点
break; // restart
// r为rightIndex结点
r = q.right; // reread r
continue;
}
//比较key与当前Node结点的k,若大于0
if (cpr(cmp, key, k) > 0) {
// 向右移动
q = r;
r = r.right;
continue;
}
}
if ((d = q.down) == null)//q的down域为空,直接返回q对应的Node结点
return q.node;
// 向下移动
q = d;
// d的right结点
r = d.right;
}
}
}
findPredecessor函数主要流程如下:
从头结点(head)开始,先比较key与当前结点的key的大小,若key大于当前Index结点的key并且当前Index结点的right不为空,则向右移动,继续查找;若当前Index结点的right为空,则向下移动,继续查找;若key小于等于当前Index结点的key,则向下移动,继续查找。直至找到前驱结点。
3.findNode()函数
private Node<K,V> findNode(Object key) {
if (key == null)
throw new NullPointerException(); // don't postpone errors
Comparator<? super K> cmp = comparator;
outer: for (;;) {
//同样,会先找到前驱节点b,n为当前节点
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
Object v; int c;
if (n == null)
break outer;
Node<K,V> f = n.next;
if (n != b.next) // inconsistent read
break;
if ((v = n.value) == null) { // n is deleted
n.helpDelete(b, f); //辅助删除
break;
}
if (b.value == null || v == n) // b is deleted
break;
if ((c = cpr(cmp, key, n.key)) == 0)
return n;
if (c < 0)
break outer;
b = n;
n = f;
}
}
return null;
}
findNode函数里边的代码于doPut里边的代码如出一辙,可以直接参照来看即可。
4.doRemove()函数
// 移除一个结点
final V doRemove(Object key, Object value) {
if (key == null)
throw new NullPointerException();
// 保存比较器
Comparator<? super K> cmp = comparator;
outer: for (;;) { // 无限循环
//根据key找到前驱结点,n为当前Index结点
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
Object v; int c;
if (n == null)
break outer;
Node<K,V> f = n.next; // f为当前结点的next结点
if (n != b.next) // 不一致,重试 (inconsistent read)
break;
//当前结点的value为空,需要删除
if ((v = n.value) == null) { // n is deleted
// 删除n结点
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n) // b is deleted
break;
if ((c = cpr(cmp, key, n.key)) < 0) //key小于当前结点的key
// 跳出外层循环
break outer;
if (c > 0) { // key大于当前结点的key
// 向后移动
b = n;
n = f;
continue;
}
//如果传入了value,需要判断vale是否相等
if (value != null && !value.equals(v))
break outer;
/**
*下面三个步骤才是整个删除操作的核心
*第一步,尝试将待删结点的 value 属性赋值 null,失败将退出重试
*/
if (!n.casValue(v, null))
break;
/**
* 第二步和第三步如果有一步由于竞争失败,
*将调用findNode方法根据我们第一步的成果来进行删除,
*也就是删除所有 value 为 null 的结点
*/
if (!n.appendMarker(f) || !b.casNext(n, f))
findNode(key); // retry via findNode
else {
//添加节点并且更新均成功
// 利用findNode函数的副作用,删除n结点对应的Index结点
findPredecessor(key, cmp); // clean index
if (head.right == null) // 头结点的right为null
// 需要减少层级
tryReduceLevel();
}
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
}
return null;
}
doRemove函数的处理流程如下:
① 根据key值找到前驱结点,查找的过程会删除标记为删除的结点。
② 从前驱结点往后查找该结点。
③ 在该结点后面添加一个marker结点,若添加成功,则将该结点的前驱的后继设置为该结点之前的后继。
④ 头结点的right域是否为空,若为空,则减少层级。
doRemove操作具体如下图:
或
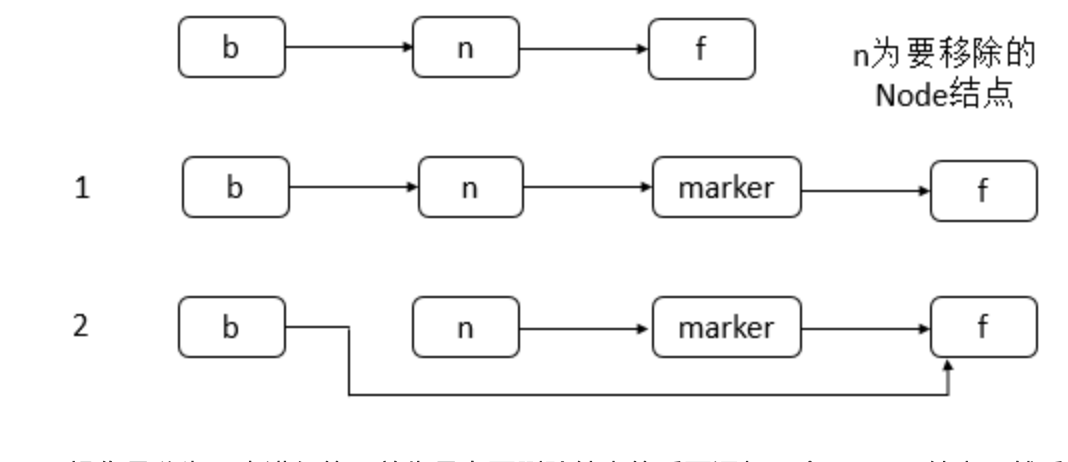
可以看到doRemove操作是分为两步进行的,首先是在要删除结点的后面添加一个marker结点,然后修改删除结点的前驱结点的next域。在删除完成之后,可能会调用tryReduceLevel函数进行降级操作,具体代码如下:
5.tryReduceLevel()函数
// 减少跳表层级
private void tryReduceLevel() {
// 保存头结点
HeadIndex<K,V> h = head;
HeadIndex<K,V> d;
HeadIndex<K,V> e;
if (h.level > 3 &&
(d = (HeadIndex<K,V>)h.down) != null &&
(e = (HeadIndex<K,V>)d.down) != null &&
e.right == null &&
d.right == null &&
h.right == null &&
casHead(h, d) && // try to set
h.right != null) // recheck
casHead(d, h); // try to backout
}
如果最高的前三个HeadIndex不为空,并且其right域都为null,那么就将level减少1层,并将head设置为之前head的下一层,设置完成后,还有检测之前的head的right域是否为null,如果为null,则减少层级成功,否则再次将head设置为h。
6.doGet()函数
private V doGet(Object key) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer: for (;;) {
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) { // 根据key找到前驱结点,n为当前结点
Object v; int c;
if (n == null) // 当前Index结点为null,跳出外层循环
break outer;
// f为当前结点的next结点
Node<K,V> f = n.next;
if (n != b.next) // 不一致,重试 // inconsistent read
break;
if ((v = n.value) == null) { // n is deleted
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n) // b is deleted
break;
if ((c = cpr(cmp, key, n.key)) == 0) { // 找到key值相等的结点
@SuppressWarnings("unchecked") V vv = (V)v;
// 返回value
return vv;
}
if (c < 0) // 小于当前结点
// 则表示没有找到,跳出外层循环
break outer;
// 继续向后移动
b = n;
n = f;
}
}
return null;
}
doGe函数整体来说比较简单,而且前一部分的判断模块在doPut方法里边都有,在此不再赘述。其只要流程如下:
①先找到对应的前驱节点
②对前驱节点以及自身节点进行多次判断
③若所有判断都通过则返回当前节点的值
④如果都没有找到则返回null
根据图片看一下doGet大致流程:
比如我们查找元素9,大致流程如下:
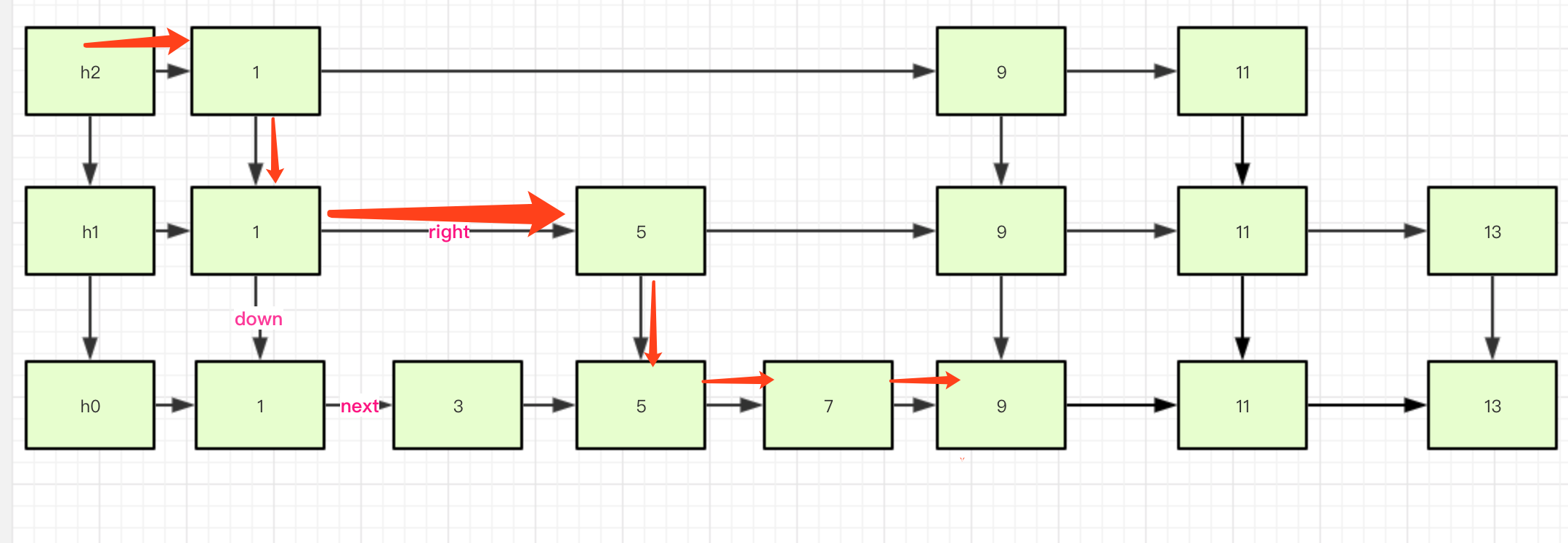 为啥不从9的索引直接过来呢?
为啥不从9的索引直接过来呢?
这个是由于findPredecessor()方法返回的是当前节点的前驱节点,具体为什么要这样走,评论区等你们回答!
其他相关函数 1.size()函数
public int size() {
long count = 0;
//找到第一个结点
for (Node<K,V> n = findFirst(); n != null; n = n.next) {
if (n.getValidValue() != null) //n结点没有被标记删除
++count;
}
return (count >= Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int) count;
}
首先利用findFirst函数找到第一个value不为null的结点。然后开始往后遍历,调用Node结点的getValidValue函数判断结点的value是否有效,有效则计数器加1。
2.findFirst()函数
final Node<K,V> findFirst() {
for (Node<K,V> b, n;;) {
//根据ConcurrentSkipListMap里边保存的head节点获取node
//如果最顶层node为null,说明整个跳表为空
if ((n = (b = head.node).next) == null)//head.node是BASE_HEADER节点
return null;
if (n.value != null)//判断改节点是否被删除
return n;
n.helpDelete(b, n.next);//说明节点n已经被标记
}
}
findFirst函数的功能是找到第一个value不为null的结点
3.getValidValue()函数
V getValidValue() {
Object v = value;
if (v == this || v == BASE_HEADER) // value为自身或者为BASE_HEADER
return null;
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
若结点的value为自身或者是BASE_HEADER,则返回null,否则返回结点的value。
4.containsKey()函数
public boolean containsKey(Object key) {
return doGet(key) != null;
}
containsKey方法里边调用的是doGet方法进行判断,其时间复杂度也是O(log2n),想一下这个于HashMap里边的containsKey方法有什么不同
5.keySet()函数
public NavigableSet<K> keySet() {
KeySet<K> ks = keySet;
return (ks != null) ? ks : (keySet = new KeySet<K>(this));
}
//KeySet里边的iterator函数
public Iterator<E> iterator() {
if (m instanceof ConcurrentSkipListMap)
return ((ConcurrentSkipListMap<E,Object>)m).keyIterator();
else
return ((ConcurrentSkipListMap.SubMap<E,Object>)m).keyIterator();
}
keySet看源码你会发现,它其实就是把当前ConcurrentSkipListMap当作参数传入使用,其里边的方法还是调用的当前ConcurrentSkipListMap对象
6.values()函数
public Collection<V> values() {
Values<V> vs = values;
return (vs != null) ? vs : (values = new Values<V>(this));
}
// 获取size方法
public int size() {
return m.size();
}
与keySet一样,都是调用其引用,对当前对象的一些操作。
总结
ConcurrentSkipListMap 是一个基于SkipList实现的并发安全, 非阻塞读/写/删除的Map,
ConcurrentSkipListMap与ConcurrentHashMap 不能比拟的优点:
1.ConcurrentSkipListMap 的key是有序的。
2.ConcurrentSkipListMap 支持更高的并发。
3.ConcurrentSkipListMap的存取时间是log2n,和线程数几乎无关。也就是说在数据量一定的情况下,并发的线程越多,ConcurrentSkipListMap越能体现出他的优势。
引用文献:
1.死磕 java集合之ConcurrentSkipListMap源码分析
2.基于跳跃表的 ConcurrentSkipListMap 内部实现(Java 8)
3.【JUC】JDK1.8源码分析之ConcurrentSkipListMap(二)
4.ConcurrentSkipListMap 源码分析 (基于Java 8)